pnpm 文件存储原理和 node resolve 的关系
最近在工作上排查了一个 monorepo 场景 node resolve & pnpm 的问题,虽然老中医手法,随便试了两下就解了,但是信奉西医编程的我还是花了不少时间定位根本的原因,本文简单总结一下相关内容
西医编程 Yes!
中医编程No!(🤣本文前需要前置了解 “npm 幽灵依赖” & "pnpm",不了解的话快搜一下相关文档吧~
最近排查了一个依赖解析的问题,过程中又重新理解了一下 pnpm 文件结构以及 node 对 module resolve 的方式。
背景是一段代码里通过 require 的方式调用一个包,我明明已经安装了这个依赖,但是 require 还是无法找到这个 module,就非常奇怪。
其实根本原因就是这个包使用了一个自己定制的 require,而不是 node 提供的,寻找 module 的方式和原生 node 不同,最终导致出现问题。问题虽简单,但是背后的一些问题还是值得好好记录一下。
pnpm 是如何组织 node_modules 的?
具体其实可以参考这个官方文档 基于符号链接的 node_modules 结构 | pnpm,这个文档里已经比较清楚的描述了这部分。
node_modules
├── foo -> ./.pnpm/foo@1.0.0/node_modules/foo
└── .pnpm
├── bar@1.0.0
│ └── node_modules
│ ├── bar -> <store>/bar
│ └── qar -> ../../qar@2.0.0/node_modules/qar
├── foo@1.0.0
│ └── node_modules
│ ├── foo -> <store>/foo
│ ├── bar -> ../../bar@1.0.0/node_modules/bar
│ └── qar -> ../../qar@2.0.0/node_modules/qar
└── qar@2.0.0
└── node_modules
└── qar -> <store>/qarpnpm 对每一个唯一版本的 npm 模块都在 store 目录进行的存储。在项目实际执行 install 时,会通过 symlink & hardlink 的方式去构建项目的 node_modules 依赖。
node 是如何 resolve 一个模块的?
pnpm 为什么要做这种目录结构?为什么使用了这种方式去构建 node_modules 就能解决 node resolve 时的幽灵依赖问题?
这个时候我们就得先来理解一下,当我们在调用 require 方法时,node 到底是如何处理的?
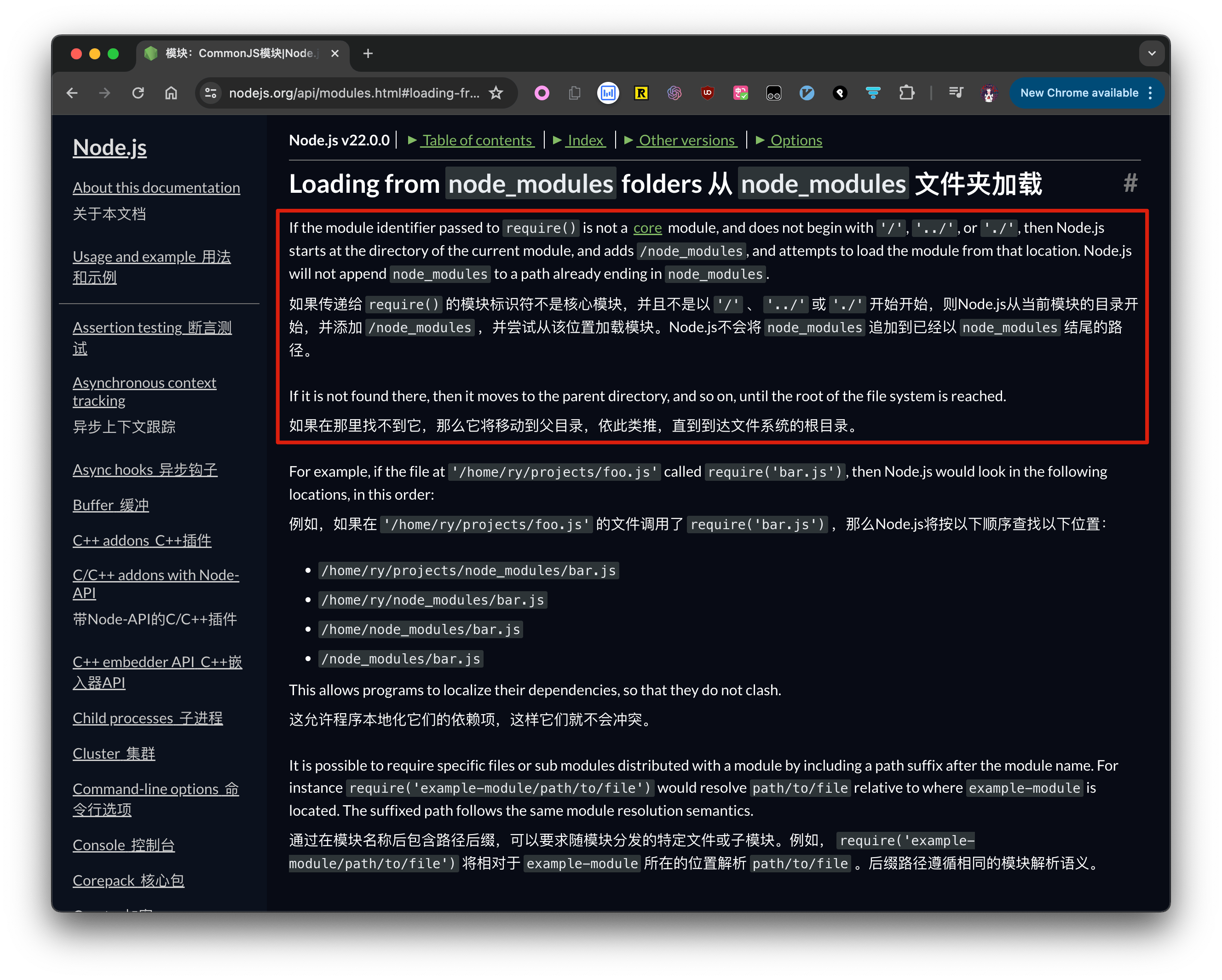
从官方文档(Loading from node_modules folders)中我们可以找到 node module 对于一个 module 是如何索引的。
简单来说,node 在 resolve module 时,会持续解析外层的 node_modules 文件夹,直到无法找到任何 node_modules 文件。
pnpm 如何解决幽灵依赖的问题通过上面的文件结构也很容易理解。由于 node 在 resolve module 时,会持续解析外层的 node_modules 文件夹,所以这种组织模式就可以解决幽灵依赖的问题。
node 的 resolve 针对 pnpm 中 symlink 的文件如何处理?
虽然已经知道 node 是如何 resolve 一个 module 了,但是这个时候如果再叠加上 symlink 和 hardlink 呢?node 这时候又会如何处理呢,会根据什么 path 来寻找 module?
是会基于 pnpm store 中的源文件的地址?还是基于 hardlink 的文件地址?或者是基于 symlink 后的文件地址呢?
只有搞清楚了这些,才能在遇到 pnpm 解析问题时,快速定位到问题根本原因所在。
想要搞清楚这些,我们需要区分几种场景:
- 项目目录下去 import/require 一个 node_modules 内的 module
- node_modules 中的 package 中,有代码 import/require 其他 package module
先来看 case 1: 项目目录中 require 一个 node_modules 内的 module,node 如何处理?
node_modules
├── foo -> ./.pnpm/foo@1.0.0/node_modules/foo
└── .pnpm
├── bar@1.0.0
│ └── node_modules
│ ├── bar -> <store>/bar
│ └── qar -> ../../qar@2.0.0/node_modules/qar
├── foo@1.0.0
│ └── node_modules
│ ├── foo -> <store>/foo
│ ├── bar -> ../../bar@1.0.0/node_modules/bar
│ └── qar -> ../../qar@2.0.0/node_modules/qar
└── qar@2.0.0
└── node_modules
└── qar -> <store>/qar我们可以再用这个目录结构来看,假设我们项目中写了如下代码:
const foo = require('foo');node 是怎么找到 foo 这个 module 的呢?
- 首先向上找到 node_modules 文件
- 从 node_modules 中找到 foo 的文件夹
- 找到 package.json 中指定的 main 文件
- 成功加载依赖
case 1 其实相对简单,并没有因为 node_modules 中的 foo 是 symlink 从而导致什么非预期内的结果产生。
所以再来看看 case 2:node_modules 中的 package 中,有代码 import/require 其他 package module,node 如何处理?
先说结论:在 case 2 中,如果一个 node_modules 中的代码需要执行 require,它其实是基于 hardlink 的,而不是基于 symlink。
我这里简单画了个图来加深一下理解:
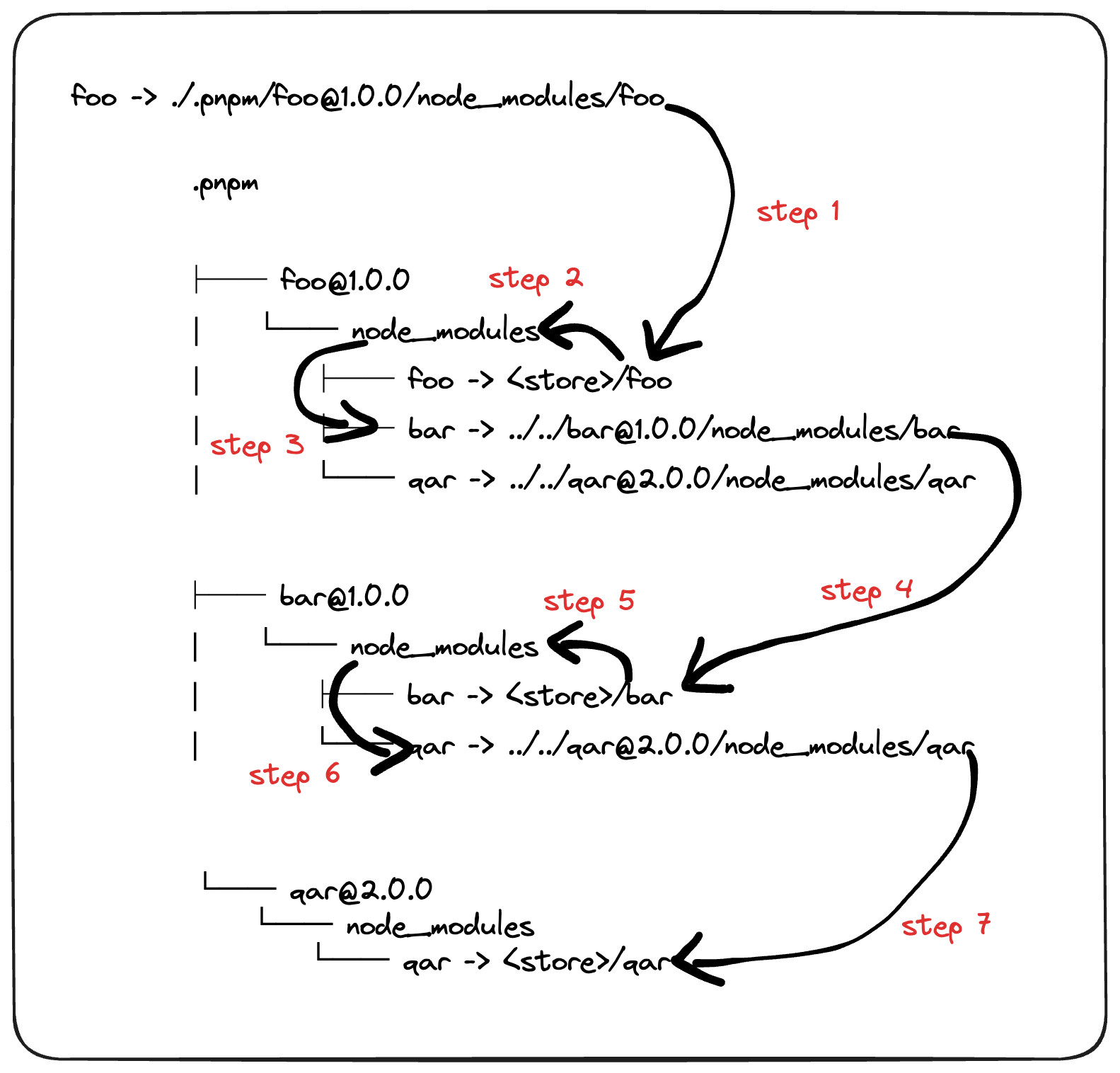
如果 node 基于 symlink 的地址来做 require 的话,按照 pnpm 的目录结构的话,就直接寄了。 foo 内部的代码如果想使用 bar 的话,直接会无法找到对应 module。
所以当 foo 中 require bar 时,会基于 foo 的 hardlink 地址去找依赖,而不是 symlink,也不是 store 中的实际文件地址。
最后
pnpm 很巧妙的利用了 symlink 来组织 node_modules 的目录结构,来避免幽灵依赖的问题。又通过 hardlink 来将 module 存储到 pnpm store 中,从而提升安装素材,减少磁盘空间的使用,太妙了。
pnpm 相关的知识点还有很多,本文也只是管中窥豹简单了解和总结一下基础原理,如果对你有任何帮助那就太好了!(我的评价是不如看官方文档,hhhh 🤣
总之,妈妈再也不用担心我不小心碰到幽灵依赖的问题啦🥹!