从 CRUD 到复杂应用,架构设计到底解决什么问题?
最近在做一个 AIGC 无限画布形态的产品(类似 Lovart),在架构上比 CRUD 页面复杂一些。
之前虽然感觉对架构有一些理解,也读过一些架构设计相关的书,但这次经历了复杂系统的设计与重构之后,算是毕竟清晰感受到了架构设计的意义,也感受到了复杂系统和和普通 CRUD 页面的区别,以及架构设计到底在解决什么问题,挺有趣的,所以简单整理一下。
架构设计在解决什么问题?
首先,架构设计的本质是什么呢,它到底在解决什么问题?先说结论:
以我的理解来看就是 “通过某种代码的组织方式,来解决系统复杂后迭代效率变慢的问题。”
如果一个系统特别简单,例如只做简单的信息展示,一个代码文件就解决掉了,何谈架构呢,如果硬要去做设计,就是过度设计,反而还提升了理解和实现成本。
只有当系统足够复杂,例如数据模型足够多相互耦合、功能相互依赖、能力自由组合,才需要进行架构设计来解决复杂系统才会存在的问题。
所以接下来就可以先看,简单与复杂系统的区别。简单/复杂,他们都是主观形容,容易理解上有偏差,所以需要客观的事实场景举例下,这样比较有体感,更好理解。
什么是简单系统,什么是复杂系统?
这里暂时只讨论前端系统。
从我个人的经验来看,简单系统大概有这些:
- 普通后台管理系统
- 简单官网展示页面
- 活动页
- 数据展示页
- 生命周期很短的业务页面
简单系统的共性,大多都是页面上的业务逻辑不复杂,页面看起来很多,但每个页面都非常独立,代码行数也不多,交互形态较简单。
或者一些官网/活动页面看起来很炫酷,但是都是展示,状态简单,没有业务逻辑,维护成本低,日抛形页面,这些之前在 AI 没流行之前,基本上都是低代码搭建的重灾区。
噢,说到低代码,其实我们也可以理解,只要能被之前的低代码系统覆盖的,基本都是简单系统,哈哈哈哈。谁的低代码系统能覆盖一个复杂系统呢?基本没见过。
而复杂系统的话,则区别于上面那些(是不是低代码搭不出来了🤣):
- Figma、Canva 这类画布和设计产品(最近在做的画布产品可以放在这一类)
- 飞书文档、腾讯文档、Notion 这类文档产品
- 千牛、抖店商家后台这类大型平台系统
- 商品发布、复杂权限后台、多人协作系统
他们的复杂性,基本上都来自于,在一个模块中进行长期的迭代,业务规则、数据模型、功能交互等,不能像前面的简单系统一样,可以被无数的页面切割。它们都是需要被长期持续迭代的。
为什么常见的 CRUD 应用的复杂度为什么很低?
我在做新版架构的过程中,一直在思考,为什么之前没有这种明显的被感觉到复杂度持续提升,不做一个好的架构就无法高效迭代小去的感觉?(手动叠甲:其他场景有一些,但不多,因为多少也会做一些简单的系统设计。)
本质上还是因为,一般 CRUD 后台的复杂度天然被页面切割开来,就算我们不考虑模块的分离、业务领域的解耦,我们乱写一通,最终页面总是能跑起来,并且以后也不用再管了,因为业务不再迭代这个页面了(俗称日抛形页面🤣)。
当我们做下一个需求时,我们已经在写新的页面了,旧的页面写的多差也和新的页面没什么关系。
在前端,CRUD 应用的复杂度天然被页面切割了。
这就是为什么一般 CRUD 不需要很复杂的架构设计也可以跑的很好的原因。一张图看明白:
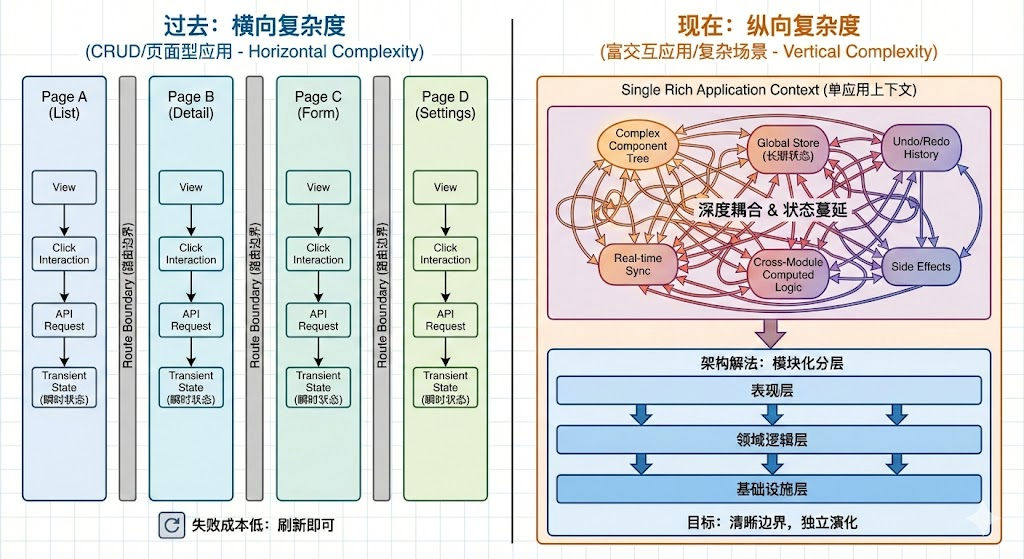
但当我们开始去做一些复杂应用的时候,一切债务都将在此刻进行偿还,没踩的坑现在开始踩,没吃的屎现在统统开始吃。就像图片中的右上角耦合的状态,当数据模型多、状态变更多、用户行为足够灵活&丰富,且都在一个页面中供用户进行操作时,例如飞书文档、Figma、富文本,不好好设计一下,应用将无法再被继续维护。
只能学习学习再学习,重构重构再重构了,这就是我在做复杂应用时候的现状。
复杂系统为什么维护困难?
复杂应用的难点在于:所有东西都在同一套模型上持续叠加叠加再叠加。
以一个无限画布产品为例,它可能同时涉及:
- 画布对象模型
- 图层管理
- 选区状态
- 拖拽、缩放、旋转、裁切
- 多选、组合、取消组合
- 撤销、重做
- 复制、粘贴、删除
- AI 生成任务
- 素材管理
- 历史记录
- 本地缓存
- 服务端保存
- 性能优化
- 错误恢复
- …
关键的是,这些功能是需要被组合在一起的,不是完全独立的。
例如,当实现一个旋转的时候,就必须考虑,辅助线、数据模型、元素对齐、撤销、重做等等。
没错,一个简单的旋转必须要考虑这么多,因为每一个功能都和旋转有关系🥲,旋转完成的元素对齐功能不能丢吧、数据模型得记录吧、辅助线不能因为旋转之后就没有了吧、撤销重做得支持吧…
再例如,实现一个编组能力的时候,就需要考虑:元素的拖拽、缩放、旋转、撤销、重做、复制、粘贴、性能、选取状态、功能操作等等在 group 状态下如何处理。
看起来一个功能很简单,但由于产品形态的灵活性,能力是需要和其他能力被一起使用的,就必须考虑这些能力被组合之后的处理,复杂度直接飙升。
复杂系统的难点就是,功能之间无法被轻易的解耦开来,他们在业务的逻辑上,是有关联的,相互影响的。
例如一般的表单页面,通常产品给设计规划好了,第一步填什么,填完进下一步,下一步继续填,用户会严格按照设计的规则使用这个产品,但是大多数的复杂系统不是这样的(要么就是规则太多,这也是一种复杂,哈哈)。
所以,当用户行为足够自由,功能组合足够多,数据模型足够复杂时,如果没有提前设计好边界,代码就会很快变成一团互相耦合的状态。
随着需求继续增加,最终一定会进入一个阶段:每次改动都要担心影响别的地方,每次上线都不确定哪里会炸,每个新人进来都看不懂系统为什么这么写。
所以这个时候,迭代的效率必然会无限降低,且不是能靠加人被快速解决的。
复杂应用的特征识别
再从我的个人经验来看,提取一些对于复杂系统的识别。
能够识别就能够提前做一些战略性的设计,避免屎山堆高高再彻底重构,边开车边换轮子。
从业务形态来说,又可以从这些应用中区分先分成两类复杂系统(可能不这么叫?名字后面再说吧)。
重交互、状态的系统:Figma、Canva / 飞书文档、Notion / Lovable / 商品创建 …
重平台、组织的系统:千牛&抖店商家后台 / 橙蕉管理后台
这两个系统的复杂度的原因不同,需要单独来看。因为按照前面的分析来看,一些 CRUD 的后台理论上不应该复杂,因为被页面分割了嘛。但是从我的从页经验来看,好像又不是这样。
我们先来看,重交互、重状态的系统。
这类系统往往非常灵活,用户可以自由的使用页面上的功能,功能之间相互影响、相互组合,前面也说过,所以他们就可以被抽象出来一些共性的特征。
1. 数据模型复杂且相互依赖
通常有超过 100+ 的数据状态被定义和使用,同时状态之间会相互依赖互相影响,稍有不慎,维护成本直线上升。
例如我之前维护过的抖店商品创建页,光不同的表单组件就有大几十个,表单的节点数量有几百个,也就是说会有几百个数据状态。且这些状态之间的联动关系也是非常复杂的(业务规则如此),例如修改了数据模型A例如商品类目,BCDEF 等等数据节点都要自然的发生变化,例如某些类目对商品主图有一定要求,对 SKU 有一定限制等等。这个时候整个发品页的系统必然会非常复杂。
所以当我们发现,一个模块数据模型特别多,且业务上他们的关系也会相互联动作用,整个系统必然是复杂的。
2. 功能自由灵活且丰富支持自由组合
通常提供超过 100+ 的子功能,且用户可以灵活组合使用,不被限制,Figma, Canva, 文档都是这种类型,旋转、拖拽、裁切、组合等,都是围绕一套数据模型进行实现,必然复杂。
这里的复杂度的产生其实也很好理解,因为功能可以任意组合,就需要我们在开发任意功能的时候都要考虑到所有相关联的能力如何不冲突,前面也讲解过例子,就不多赘述了,想一想就有点头晕🤣。
3. 复杂度无法被切割
有些页面看起来复杂,功能很多,但本质上功能之间毫无关联/无相互影响,那么这些页面,本质上还是简单的页面,不算复杂的系统,其实就是因为复杂可被切割。
当我们发现业务逻辑,无法被轻易的分散到各个模块/页面中时,这个时候系统一般就会往复杂的系统发展了。
4. 涉及多人协作的系统
这里指的是多人可同时操作页面,状态实时同步,就像云文档,A 改 BCD 可以同时看见,也就是多人共同协作,当需要涉及多人协作的时候,复杂度自然就提升了,因为需要考虑不同用户之间状态的实时同步、冲突如何解决等等。
实现一个基础的 Figma 已经很复杂了,但是如何还要加上多人协作呢,复杂度又提升了,直接列开,boom。
前面总结的一些特征,说的是偏重交互、灵活自由的系统中的一些复杂应用的常见的几个特征。但一些 CRUD 的系统也会复杂。
就拿我做过的抖店商家后台来说,作为这种大型中后台系统,也是非常复杂的,因为它涉及了 100+ 的子应用,复杂的权限管理系统,以及对性能&稳定性的要求特别高,同时又涉及组织架构上的跨团队的协作,这类系统也是非常复杂的。
所以可以对这类,重平台、重组织协作的系统的复杂特征再做一个总结:
1. 涉及子应用/页面数量多
一个大型的后台,就拿我们业务上的抖店商家后台来说,是一个主应用 + N 个子应用的架构。目前有 100+ 的子应用,算上活跃的路由,差不多有 1000 左右个页面。一个路由,会同时加载 N 个子模块 + 1 个子应用。
这些应用可能会有不同的接入方式,微应用(Garfish / iFrame)、微模块(Vmok / MF / ..)。
这个时候就需要考虑的就多了,简单列举一些:
- 稳定性:子应用/模块的发布会不会不小心就把整个应用带炸了,如何解决?
- 模块隔离:子应用之间如何相互不影响,主子之间如何不影响,模块之间如何互不影响?
- 性能体验:多个子模块 + 主应用 + 子应用,同时加载的时候,如何保证 INP / LCP,操作流畅 / 加载流畅?
- 应用监控:应用挂了 / 性能体验问题等等各种问题,能不能快速监控到?
- 菜单与权限:子应用的菜单应该如何控制管理、权限应该如何配置?
- 开发体验:子应用/子模块的接入成本是不是足够低,体验足够好?
- …
师傅快别念了,我已经开始有点晕了😵💫😵💫😵💫。
2. 公共变更影响面大的部分
有的时候,作为这种复杂系统的主应用,会提供一些方法给子应用/模块进行使用,例如封装好的 http 请求、业务打点能力、用户信息获取等等,这些方法看起来非常简单,甚至看起来好像没什么复杂度。
但再简单的东西,只要用的人足够多,那么就会成为系统复杂的一部分,因为必须要考虑,这些公共模块的简单变更,到底会影响多少业务。
这种平台上的公共能力,不像子应用内部的能力,一不小心改炸了,就会导致整个系统的崩溃,所以,被大量模块应用的能力,也是会让系统更复杂的原因(所以,按照经验来说,主应用非必要,不应该提供一些非必要能力给子模块使用)。
比如你改一个登录态逻辑、菜单协议、路由机制、埋点 SDK、接口封装、错误处理、布局容器,可能会影响几十甚至几百个业务页面。
所以,重平台的一些复杂度,其实也来源于平台对外提供的能力,虽然看起来好像不复杂,但是只有维护过的人才知道,维护这些模块有多痛苦,多费劲。
另外,除了上面说的一些特征,其实无论是什么样的系统,只要满足下面几个共性的条件,这个系统必然就会变的复杂,所以下面再整理一下我理解的共性复杂度特征。
1. 涉及多人工作协作
这里说的多人协作,不是指的跨组织的协作,指的是团队内多个人要共同维护一个业务模块。
一个复杂业务由多个人共同协作的时候,就必然要考虑模块之间的切割,做到如何互不影响。多个人维护一个模块,看起来肯定会更快对吧,但其实就像《人月神话》里说的,对于无法分解的系统,加人是无法带来效率的提升的,甚至消耗的时间会更长,因为沟通协作的成本,已经超过了这个人能带来的产出。
这个时候必然就依赖好的架构设计,把复杂的系统拆解开来,让每个人能独立去维护开发一个模块,这样才能提升效率。
所以涉及多人协作开发一个系统时,就需要提前想一想,什么样的设计才能真正的让大家可以紧密合作,提升效率。
所以,一旦涉及多人工作协作开发一个系统时,这个系统就会有协作的问题被解决,这也是复杂度的来源。
对了,这套其实对 AI 也一样,怎么样让更多的 Agent 可以并行开发,其实本质上是一个道理。
2. 系统稳定性要求高
一个简单的,低频使用的页面,如果出了点问题,当场修一下就好了,问题不大。但是一个 QPS 超高,核心链路的页面,但凡出 1 分钟问题的影响都是非常大的,可以想象一下,微信支付功能爆炸1分钟是什么体验🤣,支付团队直接原地爆炸。
业务足够复杂又要求不出问题时,首先就依赖完善的应用监控系统设计,我们需要针对这个系统的做好稳定性的设计。
错误监控(JS/白屏/网络)、业务监控(关键按钮点击、用户请求、接口报错等等)、发布灰度监控、发布与回滚 SOP 设计等等,都是我们需要必须靠考虑的点了。
如果公司平台有 Infra 系统的话,那我们只需要做为业务方接入这套系统就好了,但复杂的业务,但其实就算接 Infra 也有很多事情要做,针对自己的业务也需要定制非常多的业务层的监控。
如果没有的话,自建成本就更高了(好消息就是又有轮子可以造着玩了🥳)。
除了监控,针对核心的业务场景,自动化测试的要求也是必须要做的事情了,自动化测试又分为 e2e / unit test,这些都是比较费时间的事情。
很显然,这些能力都会提升系统的复杂度。
3. 产品性能要求高
一个系统除了业务上的功能实现,同时又需要保障应用的性能优秀,本身就是一件复杂的事情。如果系统本身不复杂,但是为了性能体验,加了 SSR, ServiceWorker, 性能监控等功能,复杂度又上升了。
如果系统本身已经很复杂了,那考虑的就更多了,因为稳定性+体验+业务逻辑其实也可以理解为功能的组合,会带来新的复杂度。
最后总结一下,区分一个系统是否复杂的特征可以有很多,上述是我工作几年能看到的一些明显的特征,如果要快速区分一个系统是否复杂的话,其实我们就看:
- 数据模型是否复杂,是否相互影响
- 功能是否足够多,是否支持自由组合
- 业务逻辑是否能够被模块/页面切割
- 系统是不是由多人一起协作开发
- 对于中后台,则看子页面/模块到底有多少
- 对产品稳定性、体验性能有没有极致的要求
- …
复杂系统不做好架构设计,会导致什么问题?
系统一旦复杂,且无任何架构设计的话,我们最直观感受到的问题就是维护成本的指数级上升,迭代效率越来越慢,也就是我们常常说的屎山。
一个简单的系统,我们可以用非常简单的方式来实现,什么业务数据获取、状态管理、UI 交互与渲染,统统一个文件一把梭就完事了,可能稍微好一些的,根据这些能力的区别,简单拆几个文件,就算不错的了,对于日抛形的页面,完全没问题,甚至可以说,这就是最好的方案。
因为它简单、直接、交付快。
但是当我们在维护一个复杂系统的时候,如果还是按照刚才的方式做的话,有经验的工程师应该都知道,迭代效率会逐步降低,阅读和修改代码的成本会持续升高,直到系统完全无法维护。
那么为什么会出现这样的问题呢?
复杂度持续提升,代码耦合严重,最终迭代效率降低。
代码耦合严重,无关的逻辑像蜘蛛网一样,相互缠绕在一起,工程师应该都有过的体验是,想增加一个逻辑,但是完全不知道在哪里加,因为代码实在太复杂了…
想改动一个代码,但是又不敢动,因为完全不知道一段代码会对多少地方产生影响,尤其是对状态的变更,太空白了。
拿前端最场景的 useEffect 来说,有些代码非常喜欢通过 effect 来实现一些业务逻辑,于是代码里就出现非常恐怖的,一个 useEffect 的 effect 有 10+ 个 props …,crazy,真的有人能知道每个 prop 对这个 effect 带来的影响吗,反正我是不行😵💫(甚至有些 props 是通过 Context Provider 传进来的,你压根不知道什么时候这个 prop 被变更了)。
同时,因为没有做好架构上的设计,复杂的系统又会出现的常见问题:
- 多人维护困难:模块之间相互耦合,一个人开发本身就很辛苦了,想到好不容易理清楚的逻辑,补充的一些代码,还要和其他和一起合代码…
- 自动化测试困难:逻辑相互耦合,导致一段函数、一个状态、一个 ui 组件,他们都包含了太多的能力,这就导致他们由太多的组合,测试难度非常高,甚至无法自动化去测。例如当我想测试一段逻辑的时候,发现它被耦合在 react 组件中,这咋测… 最后只能靠 e2e 去测能力,但是 e2e 的成本又太高了
- 稳定性通常较差:又因为代码之间耦合严重,导致牵一发动全身,就像大家都看过的梗图,修好了bug A,但是导致了 bug BCD,修是不可能修完的
常见的架构设计的方式
还是只聊前端,但我理解,软件工程的本质理应是相通的。
对于解决复杂度来说,会有一些共性的架构设计方案,但方案的选择,我理解的是没有最好的方向,只有最合适的架构方案。
所以下面列举的只是一些常见的方案,在合适的场景中就可以使用他们去解决一些问题。
对系统进行分层架构,降低耦合
从上面的分析来看,我们应该都能理解耦合对效率的影响有多严重,所以架构设计的最简单、常见的方法就是对应用进行抽象分层。
对于一般的应用来说,我们可以想到的大概有这些:
UI 渲染、生命周期、用户行为、全局事件、领域模型、领域方法、接口调用、业务规则、缓存、监控等等。
其实在实现复杂业务的时候,我们可以针对这些整体去做分层,不需要把他们耦合在一起。
一个最非常简单的例子:
拿一个 React 业务组件来说,最简单实现分层的方式是,他只做渲染,剩下的都交给其他分层模块去做,不要在 React 组件内部去实现非渲染相关的逻辑:
export function TaskEditor({ taskId }: Props) {
// 数据加载层:负责生命周期、接口请求后的数据状态维护
const taskDetail = useTaskDetail(taskId);
// 用户输入层:负责表单草稿状态,不关心业务保存逻辑
const titleDraft = useTaskTitleDraft(taskDetail.task?.title ?? "");
// 保存能力层:负责保存过程中的 loading、error、接口调用等
const saveTask = useSaveTask();
// 用户行为层:负责把“点击保存”这个用户行为编排起来
// 组件本身不实现保存细节,只拿到可直接绑定到 UI 的 action
const actions = useTaskEditorActions({
taskDetail,
titleDraft,
saveTask,
});
const task = taskDetail.task;
const loading = taskDetail.loading;
// 错误展示层:组件只负责展示错误,错误来源由各层自己维护
const error = taskDetail.error || saveTask.error;
// 领域规则层:是否可编辑由 domain 决定,UI 不直接写业务判断
const canEdit = task ? canEditTask(task) : false;
if (loading) {
return <div>加载中...</div>;
}
if (!task) {
return <div>任务不存在</div>;
}
return (
<section>
<h2>任务编辑</h2>
<div>
<label>标题:</label>
<input
value={titleDraft.title}
disabled={!canEdit || saveTask.saving}
onChange={(event) => titleDraft.setTitle(event.target.value)}
/>
</div>
<div>状态:{task.status}</div>
{error && <p style={{ color: "red" }}>{error}</p>}
<button disabled={!canEdit || saveTask.saving} onClick={actions.save}>
{saveTask.saving ? "保存中..." : "保存"}
</button>
</section>
);
}分层之后的好处其实显而易见,例如当我们需要修改数据加载的时候,我们不需要在一个 1000+ React 组件中找这个逻辑,我们只需要到数据加载那层去处理就好,易读易改。
当我们去做单测的时候,每一层也可以轻易的实现单测逻辑。
当然,上面讲的例子是一个最简单的分层的案例,对于一个包含复杂业务逻辑的 CRUD 页面算是一个简单的解法,但是当我们的应用足够复杂时,例如灵活的自由画布的时候,就需要更复杂的分层方案了,篇幅原因这里不过多展开。
分层的本质,其实就是将功能相互隔离,每一个功能处理好自己的 input / output,然后这些功能无论多复杂,都由自己内部消化,这样复杂度就不会层层叠加,每个模块只需要管好自己,同时保证自己的出入参协议不出问题就可以了。
保持单向依赖,不要反向依赖
单向依赖大概是这样:
UI 层 -> 用户行为层 -> 领域模型层UI 怎么改、交互怎么改、样式怎么改,都不应该影响 领域模型层。
这样的好处是,底层的数据模型是稳定的,例如一个无限画布中的 DataSDK、EditorSDK,他们是非常稳定的,上层的 UI 可能会调来调去,其实压根不会影响底层的数据模型。
如果不是单向依赖,那为了改动一下业务上的 UI 渲染,还需要把底层的领域模型搅一遍,那这活肯定没法干了🤣。
对了,另外还需要避免循环依赖,例如:
A 依赖 B
B 又依赖 A最后我们改代码的时候发现。
改 A 要看 B
改 B 要看 C
改 C 又影响 A导致完全没法维护,已被绕晕。
单向依赖的好处是,把容易变更的部分放到了上层,例如 UI 布局、交互行为、页面结构等等,上层随便折腾,只要还是这套业务逻辑,怎么调整都只对上层有影响,底层的 Model, Service 都是完全不会被影响的,业务你就折腾吧,俺顶得住🥳。
使用依赖注入解决系统组合
刚工作那几年,我压根看不懂 DI,什么 IOC 都啥呀,一把梭不好嘛,直到我真的开始经手搭建复杂的系统,才能理解他们在解决什么问题。
当我们对复杂系统进行抽象分层后,怎么组织这些分层后的系统又是一个麻烦的事情。这个时候就可以尝试使用 DI 来解决。
业界有很多介绍的文章,这里不再多赘述了。
设计好数据模型
这一段写的不太好,先这样,后面再改😵💫,理解的暂时不是很透彻,暂时先这样,后面有新的理解再调整。
其实无论系统多么复杂,本质上都是都是对 “数据模型” 的修改与应用。
一个画布系统里,可能会有这些核心模型:
- Canvas:画布整体
- Layer:图层结构
- Entity:画布里的元素对象,例如图片、文本、形状
- Viewport:视口状态,例如缩放比例、画布偏移
- Selection:当前选中的元素
- History:历史记录,用来支持撤销和重做
- Editor:编辑过程中的临时状态,例如拖拽中、缩放中、辅助线状态
当用户拖拽一个元素时,本质上是在修改 Entity 的位置。
当用户旋转一个元素时,本质上是在修改 Entity 的 transform 数据。
当用户缩放画布时,本质上是在修改 Viewport。
当用户选中多个元素时,本质上是在修改 Selection。
当用户撤销一步操作时,本质上是在根据 History 还原上一份模型状态。
所以,复杂应用其实在持续修改同一套数据模型。
这就是数据模型设计的价值:它能让功能变化有明确位置,明确的数据模型去承载。
如果没有设计好数据模型呢,会有什么问题?
很容易出现:哪里需要就在哪里加状态,哪个组件方便就把状态放到哪个组件里。短期看功能能跑,但随着功能越来越多,状态会越来越散,关系会越来越乱。
例如,一个元素的旋转角度,可能 UI 组件里存了一份,Store 里存了一份,接口数据里又有一份;选中状态可能被多个模块同时修改;撤销重做也不知道应该记录哪一份状态。
这时候系统就会变得非常难维护。
但如果有稳定的数据模型,大家都使用拿一份就可以了,非常方便,多人维护的时候,也好理解,大家都看的懂。
UI 可以变化,交互可以变化,接口协议也可能变化,但核心数据模型应该尽量稳定,这是架构分层中,底层核心不变的模块,其实和前面的分层、单向依赖是相辅相成的设计。
对于简单 CRUD 页面,我们可以边写边调整模型,因为它的复杂度通常不会持续叠加。
但对于画布、文档、编辑器这类复杂应用,所有功能都会长期围绕同一套核心模型演进。如果模型一开始就混乱,后面每新增一个功能,都会继续把复杂度堆高。所以就必须要提前设计好数据模型,避免越迭代越难受。
当然,如果之前就没有做过类似的系统,其实一开始乱点也没事,毕竟就像没口渴,就不知道水的重要性,哈哈哈。糊过屎山,才知道屎山带来的问题有多痛。
做好自动化测试
在 AI 时代,TDD 的开发方式我理解更重要了,一个是当前的变更对历史业务逻辑的影响可以被快速发现。另外更重要的一点是,TDD 给了 Agent 自行 Loop 的能力,他可以自己通过自动化测试的结果来自行验证,而不需要靠人来操作再告诉 AI 行不行。
而想做好自动化测试,架构分层就显得足够重要,因为当一个系统符合高耦合低内聚的话,就无法被轻易的进行测试,又和前面的设计关联起来了,哈哈。
具体测试的方式,又可以分为 e2e 和单测,我们两种都要覆盖,一个覆盖的是每个功能是否稳定不出问题,e2e 则是保证这些功能组装之后,不出问题。
避免过度设计
就像最前面说的,当一个系统足够简单的时候,不需要考虑那么多,例如只是做一个非常简单的活动展示页,我们需要做那么多分层架构么?什么 DI、单向依赖、数据和UI解耦,统统不考虑,一个文件一把梭才是最快的,过度设计纯粹浪费时间。
没有最好的,只有最合适的,所以在碰到不同的场景的时候,不要过度设计,没必要,有的时候,简单的才是最好的。
从 AI 时代再看架构设计
有了 AI,还需要学习架构设计吗,用 AI 一把梭不就完了么?
从长期来看,我也不知道。但是当前,明确业务问题之后,当问题/系统足够复杂时,还是需要人来帮助 AI 做判断的,我不知道未来还需要不需要,但是起码现在是需要的。
所以现状来说,还是需要理解架构设计,理解不同的方案解决什么问题,在 AI 给到我们 N 个方案的时候,能够选出最合适的方案,就是我们能够提供的价值吧。
最后
本文也只是对架构设计相关问题的一个简单总结,不成体系,也不够严谨。更多是基于个人实践之后的一些理解总结。
如果有时间的话,我其实推荐直接看书,例如《软件设计哲学》《人月神话》《代码整洁之道》等等,或者真的实践去做一些复杂的系统,例如实现一个简单的富文本编辑器,再结合阅读 + AI 一起沟通学习找到最优解,比看我的总结有效的多,哈哈哈。